Localization via a range finder
In our last experiment, we simulated a robot with three color sensors pointed in different directions. In each of the tests, the robot easily localized itself. But in most robotics applications, robots often have distance data to its surroundings, instead of color information. We see this in simple robots that use ultrasonic range finders to detect walls and nearby objects. We also see this in complex platforms, e.g., self-driving cars often have rotating LIDAR(s) on top of the vehicle. This system maps the immediate neighborhood around the robot car. The LIDAR data output is typically a point cloud, indicating different points in the environment and their distances from the LIDAR. We will explore this range-based mechanism in a simplified simulation.
Simulation setup
We will not recreate a continuous point cloud. Instead, we will simply replace the color data from the three sensors in the previous post with distance information. We will also simplify the problem by assuming that a diagonal distance between cells is equal to the lateral or vertical distance between cells. This assumption is not an issue as long as the method of measurements is consistent when pre-storing map information and while navigating.
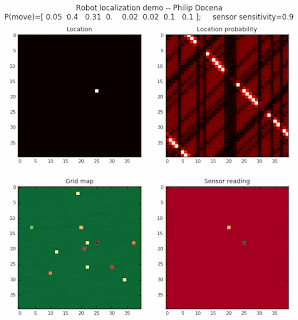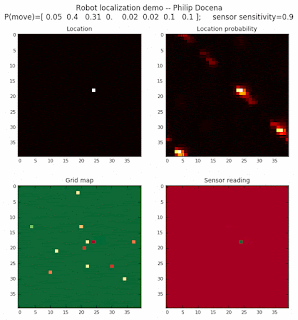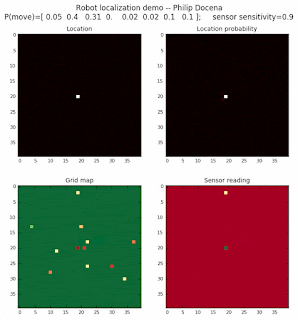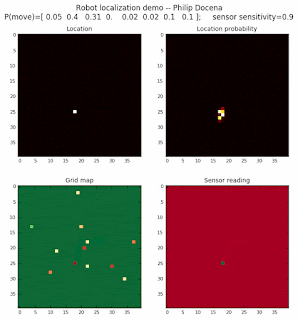
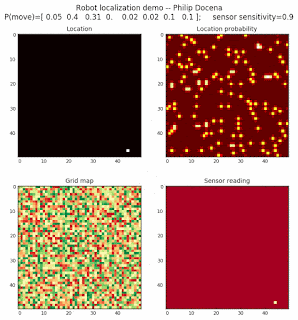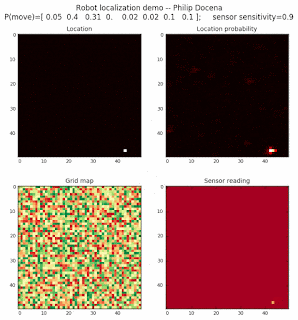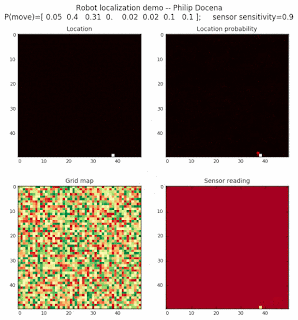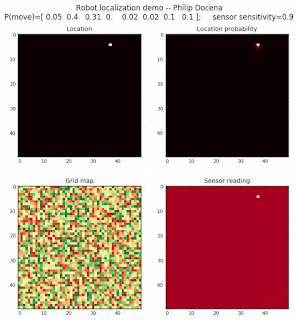
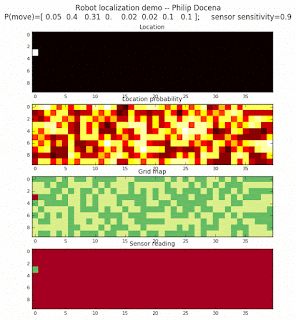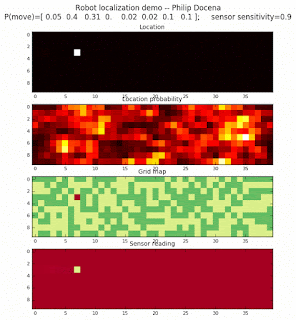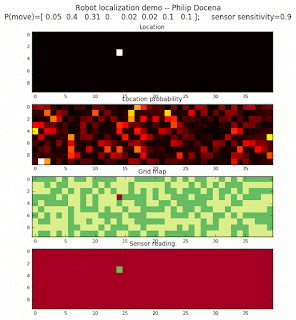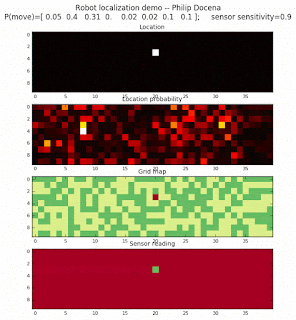
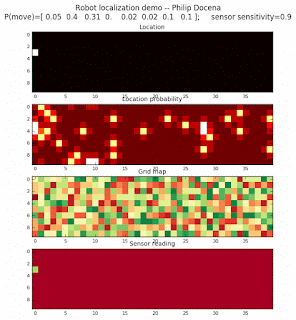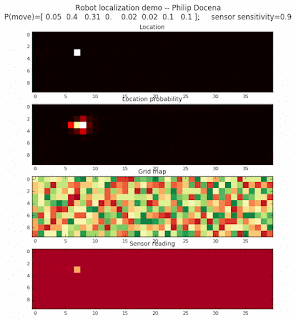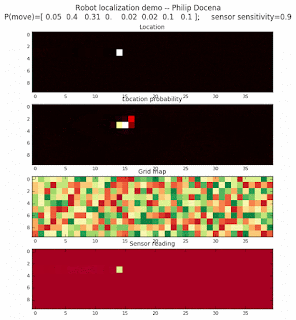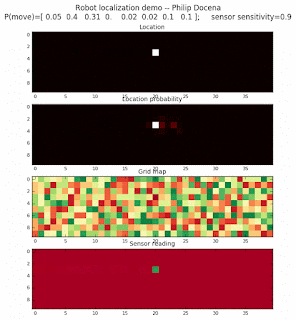
To show the changes in the distance data, we will make a slight change in the graph. We now put the location of the robot and the objects cells detected by the range finder in the first graph (upper left), and place the probability estimates on the lower right graph. The lower left remains the same, the map of the environment and the robot. On the upper right, we introduce a new graph where we plot (via a histogram) the detected distances for each of the three
Simulations
Our simulations will involve two runs, the first with 1 object type and the second with 2 object types. In theory, there should not be any difference in the localization between 1-object or 2-object runs since the range finder sensors cannot distinguish the object type, only its distance to the sensor. We will also test a low and high object density scenarios.
Low density runs
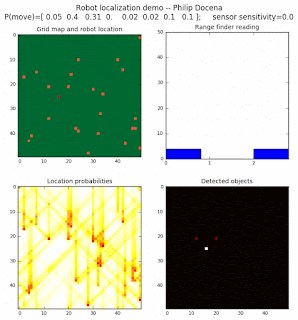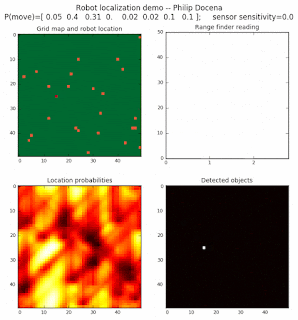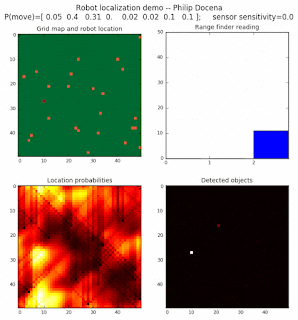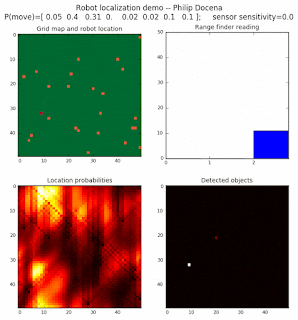
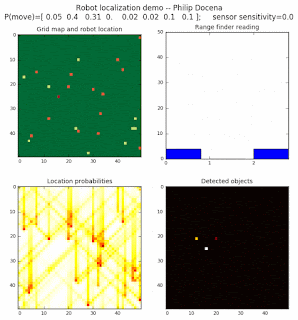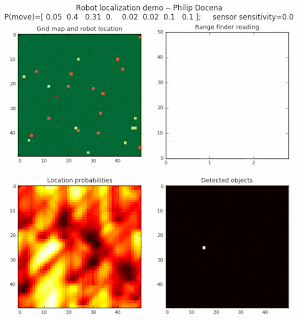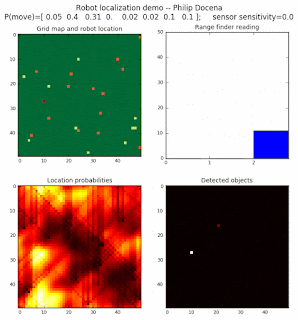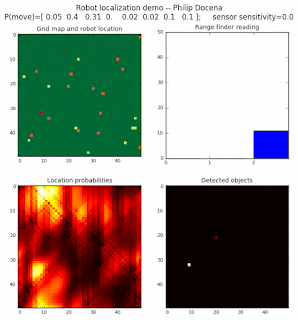
High density runs


We notice that the localization is not very precise and take many more iterations to reach a high-contrast prediction. This is expected. The number of distance possibilities that might match (or be a close match) to the current location is higher. In comparison, the very specific object type identity (via the color sensors) allows the algorithm to eliminate many cell locations as highly improbable. In a distance calculation, many more cell locations are likely locations, hence the spread out probabilities and lack of color contrast (compared to our previous simulations).
Improving the cell elimination
The problem with the above approach is that the many cells have distance calculation that are at least close to the distance measured by the range finders. Thus, they tend to maintain high probabilities as a potential robot location. One possible way to sharpen the guessing is to eliminate distance calculations that are less than a threshold away from the reported distance. This should quickly eliminate locations that are marginally viable. Let’s try this:
Low density runs


High density runs


Voila! We are able to quickly zoom in to the cells that are likely robot locations far quickly and with more contrast to neighboring cells.